
Development on Oracle Autonomous Database
Author: Donatien MBADI OUM, Oracle Consultant
1.
Introduction
In this section, we are going to talk
about the recently released Autonomous JSON Database (AJD). Oracle makes it
easy to develop JSON-centric applications. We will also talk about how you can
create graph models from data in your database. You can perform graph analysis,
develop graph visualizations and graph application and then share your results.
We will show you how you can expand your data ecosystem by integrating the data
warehouse with data lake object storage.
After that, we show you how to perform
linguistic analysis on documents and search text using Oracle Text and get
started with location intelligence analytics and mapping services using a
spatial offerings.
2.
Terms and concepts
ADB supports the JavaScript Notation,
also known as JSON, natively in the database. It supports applications that use
the Simple Oracle Document Access (SODA) API to store and retrieve JSON data or
SQL queries to store and retrieve data stored in JSON formatted data. This
concept is named as Oracle’s converged database. Oracle AJD is Oracle
Autonomous Transaction Processing (ATP) but it’s designed for developing NoSQL-Style
applications that use JSON documents.

You can promote an AJD service to ATP.
Development of these NoSQL-Style document-centric applications is particularly
flexible because the applications use schema list data; this lets you quickly
react to changing application requirements. There is no need to normalize the
data into relational tables and no impediment to changing the data structure or
organization at any time. A JSON document has its own internal structure, but
no relation is imposed on separate JSON document.
AJD give you the ability to create
highly complex SQL-based queries for reporting and analysis purposes. It has
built-in binary JSON storage type which is extremely efficient for searching
and for updating. It also provide advanced indexing capabilities on the actual
JSON data. It’s built on ADB so that gives you all of the self-driving
capabilities for ADB.
3.
Introduction of JSON Document
JSON stands for JavaScript Object
Notation. It was originally developed as a human readable way of providing
information interchange between different programs. A JSON document looks like
this:
{
"id":
"0001",
"type":
"donut",
"name":
"Cake",
"ppu":
0.55,
"batters":
{
"batter":
[
{
"id": "1001", "type": "Regular" },
{
"id": "1002", "type": "Chocolate" },
{
"id": "1003", "type": "Blueberry" },
{
"id": "1004", "type": "Devil's Food" }
]
},
"topping":
[
{
"id": "5001", "type": "None" },
{
"id": "5002", "type": "Glazed" },
{
"id": "5005", "type": "Sugar" },
{
"id": "5007", "type": "Powdered Sugar"
},
{
"id": "5006", "type": "Chocolate with
Sprinkles" },
{
"id": "5003", "type": "Chocolate" },
{
"id": "5004", "type": "Maple" }
]
}
A JSON document is set of Fields;
each of these fields has a Value and those values can be of
various data types. We can have simple Strings,
Integers, Real numbers, Booleans, Date, Null values.
Additionally, values can be Objects
and objects are whole JSON documents embedded inside a document. There is no
limit on the nesting. Finally, we can have Arrays
and arrays can have a list of scalar data types or list of objects.
JSON documents are stored in something
called Collections. Each document may have its own schema, its own layout, to
the JSON. So this is mean that JSON document databases are schemaless but you
can a check constraint to enforce a schema constant that you wish to introduce
to your JSON data. You can also create indexes on a JSON collection and those
indexes can be of various types:
- -
Unique index
- -
Single field
- -
Compound index
- -
Flexible Search index
4.
Using AJD
Since Oracle database 12c, JSON
documents can be stored, queried, searched, updated on generated in Oracle
Database:
-
As varchar, clob, blob data type in 12c
-
As JSON data type with an efficient binary format in Cloud 19c
This allows you to combine schema
flexibility of JSON with strengths of relational model in one database system.
So you can go from one to the other and easily manipulate JSON as though it was
a relational database or relational data even though it’s JSON data. Because
you are storing the JSON in an Oracle database, you get the full benefits of
the ACID transaction model on your JSON data like you get with your relational
data.
A primary unit of storage for JSON is
a Document. Each document has a key
associated with it and we can use that key to do a CRUD (Create, Read, Update,
Delete) operations. We can query the document using Query by Example language,
so we don’t need to use or even know SQL to be able to query that document. A
group of documents is called a collection, so documents live inside the
collection. The collection is identified by a name and a group of collection is
known as the database; within an Oracle relational model, that is represented
by a schema. So each schema can represent one database. A document is like a
Row and a collection is like a Table. A JSON document itself is represented by
a row in an Oracle table:

We
have there, its key and a few metadata columns like the version, the creation
date and the last modified date.
- AJD is built JSON-centric application document:
- Accessed via document APIs
- SQL foe cross-collection queries, reporting and analysis
- Native JSON storage, in-memory optimizations and advanced
indexing
AJD
is based on the common ADB platform:
- -
Fully managed database, No DBA required
- -
Instant autos calling
- -
Lifecycle operations controlled via interface, APIs and CLIs
- -
One-button in-place upgrade to full ADB for multi-model
workloads
AJD
contains (virtually) ALL functionality of ATP and ATP contains ALL
functionality of AJD. The difference between AJD and ATP are:
- -
AJD is limited to 20GB of storage outside of SODA JSON
collections
- -
AJD cannot store a heterogeneous collection (i.e. JSON and
non-JSON documents) via SODA
- -
AJD is lower in cost (priced same as ATP BYOL, but license is
included)
So what is SODA?
It’s a set of NoSQL APIs and it’s
provide for a number of different programming languages (Java,
JavaScript/Node.js, Python, REST, PL/SQL, C). Through SODA, you can create
collections, store documents to those collections, retrieve documents by key,
or query them using a simple Query by Example syntax. And then, there is no
need to know SQL in order to use SODA.
So what is SQLcl?
It’s
a modern SQL Developer Command Line Interface for Oracle Database that provide
inline editing, statement completion and command recall. It can also use SODA
commands.
Let’s
present you the solution architecture used by AJD:

On the top, we have the user view of
the application and they might be running a web application, mobile application
or any other simple user-friendly API.
In the middle, we have application
code, which will be running in Oracle’s container engine for Kubernetes, also
known as OKE. This allow applications to be built using Docker containers.
Those containers are transferred over to OKE, which takes charge of them and
provides full container management capabilities.
Now those applications running in OKE
would talk to the JSON document store via SODA API.
To the right of that, we can see that
you can also do SQL-based reporting which connect directly to the Oracle
Database over SQL*Net.
So
the development flow for developer is:
-
Provision your database using the Web interface, Command Line
or REST API
-
Create local Docker container where you can do the bulk of
development work and it’s local on your machine
-
Develop in Docker connecting Autonomous document DB
-
Deploy Docker container to Oracle Container for Kubernetes.
OKE will then take over the maintenance of your Docker container. It will look
after running multiple copies of it as is necessary. If any of those copies
crash or go down for any reason, it will simply spool up new versions.
Example of application:

5.
Using Oracle Text
Oracle database in not only a relational
store but also a document store. You can load test and JSON assets along with
your relational assets in a single database. Traditionally, Oracle has been all
about SQL development, but SQL language does take some advanced knowledge to
make the best of it. So SQL requires you to define your schema up front and
making changes to that schema could be a little tricky and sometimes highly
bureaucratic task. In contrast, JSON allows you to develop your schema as you
go, by imposing less rigid requirements on the developer. It allows you to be
more fluid and Agile development style.
Oracle text use standard SQL to index,
search and analyze text and documents stored in the Oracle Database, in files
and onto the web. It can perform linguistic analyses on documents as well as
search text using a variety of strategies, including keyword searching, context
queries, Boolean operations, pattern matching and mixed thematic queries like
HTML/XML session searching and so on. It can also render search results in various
formats including unformatted text, HTML with term highlighting and original
document format.
Oracle text supports multiple
languages and uses advanced relevance-ranking technology to improve search
quality. It also offers advantage features like classification, clustering and
support information visualization metaphors.
Finally, Oracle text provides:
- -
Indexing
- -
Word and theme searching
- -
View capabilities for text in query applications
-
Document classification applications
To create a full text index, you
create context index using the same syntax usually used, but add the phrase: Indextype is ctsys.context.
Examples:
create index ops_indx on customer(cust_comment)
Indextype is ct sys.context;
So here, we are looking at “good” and
“client” following each other:
select * from customer where contains(cust_comment,’good
client’)>0;
For JSON column jtext, we can use
textual attribute ‘description’
create index ops_indx on customer(jtext) for json;
select * from customer where json_textcontains(jtext,’$.description’,’good
client’);
Oracle text is now enabled
automatically in ADB. It provides full-text search capabilities over
Test/XML/JSON content and all the power of Oracle database and a familiar
development environment.
We can deal with text in many
different places and many different types of text. So it is not just in the
database but also outside the database. In the database, we can be looking a
Varchar2 column, LOB column or binary LOB column such as PDF or Word. Outside
of database, we might have a document on the file system or out on the web with
URLs pointing out to the document. If they are on the file system, then we
would have a file name stored in the database table and if they are on the web,
then we should have a URL or partial URL stored in the database.

We can then fetch the data from the
locations and index it in the term documents format. The basic forms we can
deal with plain text are:
- -
HTML
- -
JSON
- -
XML
- -
Formatted documents like Word, PDF, PowerPoint documents
- -
Many others types of documents.
All of those are automatically handled
by the system and then processed into the format indexing and there and we are
not restricted by the English either here.
There are various stages in the index
pipeline. A document start and taken through the different stages until reaches
the index.

- -
Data Store is responsible for actually reaching the document.
- -
The filter is responsible for processing binary documents into
indexable text
- -
The Sectioner is responsible for identifying things like
paragraphs and sentences
- -
The Lexer divide the text into indexable words
- -
The index engine is responsible for laying out to the indexes
on the disk
Storage,
Word List and Stop List are some additional inputs there. Storage tells exactly
how to layout the index on disk. Word List has special preferences like
desegmentation and then Stop List is the word that se don’t want to index.
Most
of these stages can be replaced by the user functions in PL/SQL, C code or Java
code.
6.
Spatial on ADB
Oracle spatial database is included in
Autonomous Database, allowing developers and analysts to get started easily
with location intelligence and mapping services using basic spatial search and
analysis to advanced geospatial applications and Geographic Information Systems
(GIS).
The common aspect for all spatial data
is Universal Key. Location is a universal key relating otherwise unrelated
entities.
Spatial features provide a schema and
functions that facilitate the storage, retrieval, update and query of
collections. Spatial consists of the following:
-
A schema MDSYS that prescribes the storage, syntax and
semantics of supported geometric data types
-
A spatial indexing mechanism
-
Operators, functions and procedures for performing
area-of-interest queries. Spatial joins queries and other spatial operations
-
Utility functions and procedures for validating, loading,
extracting and working with spatial data
-
GeoRaster, a feature that lets you store index, query, analyze
and deliver GeoRaster data.
Spatial data are stored as points, lines,
polygon and also imagery into ADB.
In high level of development with
spatial, we have:
-
Spatial Database APIs : SQL and PL/SQL are native in database
for working with spatial but we also have Java (SDOAPI), Python (cx_oracle),
Javascript (node-oracledb) and REST (ORDS)
-
Mid-tier Spatial Component APIs: XML and REST (Mapping,
Geocoding, Routing, Web Services [OGC] and Studio.
To load spatial data use the same
tools as for other in ADB: Data Pump and Golden Gate. You can also use a
spatial ETL tools like Safe Software FME or GDAL/OGR (Open source).
ADB natively handles JSON in general.
In-database JSON is extended to support spatial operations. SDO_GEOMETRY
constructors is extended to take JSON as input and spatial index and queries
are extended to operate on JSON documents.
What is Spatial
Studio?
Spatial Studio is a low-code self-service
application that enables you to create interactive maps and perform spatial
analysis on business data quickly and easily.
Users can visualize, explore and
analyze geospatial data stored and managed by Oracle in the Cloud or
on-premises.

Spatial studio include no additional
cost with ADB, however, requires additional compute resource to deploy. It can
run on free tier with a very small shape, just for evaluation or test. Spatial
Studio is also available on the Oracle Cloud Marketplace. Yu can also use
Spatial Studio to load spatial data into ADB. Once you have loaded your data or
accessed that already exists in your ADB, if data does not already include
native geometrics type, then you can prepare the data if it has addresses of if
it has latitude and longitude coordinates as a part of the data. Once you have
the data prepared, you can easily drag and drop and the start to visualize your
data and start to ask spatial questions.

When you done some work, you can save
your work in a project that you can return to later and you can also publish
and share the work you have done.
In addition, with the work that you do
when you perform spatial analysis using Spatial Studio, you are able to see the
SQL that was generated by Spatial Studio. You also have a GeoJSON endpoint so
you can access all the results programmatically and get the results back on
JSON.

7.
Graph on ADB
Graph is way of representing your
data. It’s a collection of points (vertices) and lines between those points
(edges). Vertices and edges can have properties.
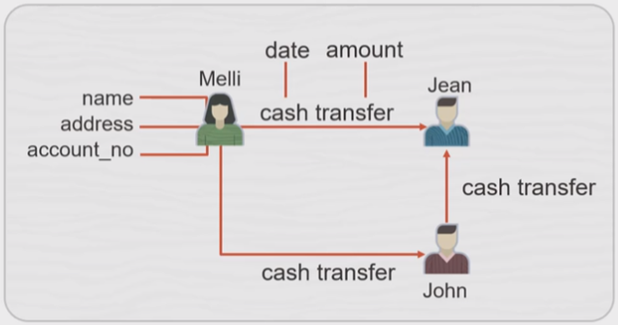
For
example, you have Melli, Jean and John who could account holders ate the bank.
And every time there is cash transfer between them. You have what is called
edges between them. So graph helps make explicit connection in your data
entities and in the properly graph data model, vertices and edges can have
properties.


Aucun commentaire:
Enregistrer un commentaire