
Monitoring Oracle Autonomous Database
Author: Donatien MBADI OUM, Oracle Consultant
1.
Introduction
In this section, we are going to show
you how monitor Autonomous Database (ADB) instances. We will talk about
monitoring ADB performance and Disaster Recovery for both Shared and Dedicated
deployment options. We are also going to talk about Auto Scaling and Auto
Indexing. At the end, we will talking about Autonomous Database connectivity to
minimize application impact.
2.
Monitoring Autonomous
DataBase Performance
The easiest way to monitor performance
in ADB is through the Clod Console. The metric resource page show real-time and
historical information about utilization of the service.

-
Storage Utilization shows the percentage of prevision
storage capacity that is currently in use. It represents the total allocated
space for all of the tablespaces.
-
CPU Utilization (%) expressed as a percentage, is
aggregated across all consumer groups. This percentage is reported with respect
to the number of CPU the database is allowed to use, which is two times the
number of OCPUs.
-
Sessions shows the number of sessions in the database.
-
Execute Count shows the number of users and
recursive count calls that executed SQL have run during the selected interval.
-
Running SQL statements shows the number of SQL statements aggregated
across all of the consumer groups during the selected interval.
-
Queued statements show the number of queued SQL
statements aggregated across all of the consumer groups during the selected
interval.
In the Cloud Console, under the
Database Dashboard, you have additional information concerning the database
instance.


-
Database Activity shows the average number of sessions in
the database using CPU or Waiting on a wait events
-
CPU utilization shows the CPU utilization for each
consumer group
-
Running statements show the average number of running
statement for each consumer group
-
Queued statements show the number of queued SQL for
each consumer group

You can also other information in the
tab data area in Performance Hub page like:
-
Activity Summary (Average Active Sessions): DB Time in units
for average active sessions
-
ASH Analytics
-
SQL Monitoring
-
ADDM (Automatic Database Diagnostic Monitor)
-
Workload
-
Blocking Sessions

In the right, you have a report dropdown
list that allows you to generate and download an AWR (Automatic Workload
repository) report.

3.
Autonomous Data Guard
(AuDG)
Autonomous Data Guard on dedicated
infrastructure is a manifestation of Oracle’s Maximum Availability Architecture
(MAA), incorporating autonomous operations of high availability best practices
found in mission critical deployments.
MAA includes key technologies such as
Real Application Clusters (RAC), Active data Guard (ADG) and Transparent
Application Continuity (TAC).
RAC enables the database to scale
horizontally for both Read and Write operations while working in tandem with
TAC to protect against the most common failures.

ADG is a database replication
technology that protects site-level outage and block-level data corruptions
that can occur. ADG provides a complete standby replica of your database to
take over in the severe disaster where entire data centers sites are lost.
However, the standby site can also be actively used for reporting during normal
operation.
ADG in the same region is part of High
Availability purpose; ADD in different regions is part of Disaster Recovery
purpose.
TAC is intelligent driver technology
that works with connection technologies (pooling, services) and data
capabilities to rebuild the session state of running transactions on a
surviving cluster node, masking hardware and software level failures, to
preserve all in-flight transactions.
On dedicated ADB, these capabilities
are autonomously operated to provide zero downtime application experience for
any kind on failure event. ADG on dedicated infrastructure includes the
following:
-
AuDG enabled at Container Creation
-
Switchover, Failover, Reinstate controls for customer
validation testing
-
Read-Only Access to the standby
-
Backup for both primary and standby database
-
Single standby target
-
2 protection modes:
o
Maximum performance (ASYNC)
o
Maximum Availability (SYNC)
4.
Monitor Auto scaling
Autonomous Database allows you to scale
up and scale down either OCPUs or Storage and allows you to do this
independently of the other. In addition to that, you can also set up auto
scaling so the database will automatically scale up to three times the base
level number of CPUs or reserved storage that you have allocated or provisioned
on your ADB.
When you create an ADB, by default
OCPU auto scaling is enabled and storage auto scaling in disabled.
Note: If you are provisioning and
always-free database, auto scaling is not enabled by default.

You can manage auto scaling by
clicking on Manage Scaling on the Database Details Page.

On ADB shared infrastructure, you can
go up to 128 OCUPs. If you need to go beyond that you would need to contact
your Oracle Support. In case of ADB dedicated, you can go beyond 128 OCPUs but
that’s a whole different conversation.
Now keep in mind that even you scale
up or down automatically or manually, the database is still open and running
and still allowing users and sessions to connect and perform their normal
workload. When scaling manually, you will just see that the status of the
database changes to SCALING IN PROGRESS.

If auto scaling is enabled and your
workload requires additional CPU resources, ADb is able to dynamically adapt
and increase the number of CPUs to meet that requirement, and this is done autonomously
meaning that it’s done with zero human intervention nor any downtime. Auto
scaling does not impact or does not influence the parallelism level or the concurrency
level of the predefined services.
When it comes to billing, you’re only
changed for the base level of CPUs that you have provisioned at any given point
in time, but when auto scaling is built, the billing is based on the average
number of OCPUs that have been consumed over the period of an hour.
Concerning the storage auto scaling,
you can use up to three times the reserved base storage. If you need additional
storage, the database automatically used the reserved storage without any manual
intervention. When the storage used is significantly lower than the allocated
storage, the shrink operation reduces the allocated storage.
Note: The shrink operation is a long running
operation and it is not available with Always free ADB.
The shrink operation requires that all
of the following apply:
-
The Storage auto scaling must be enabled
-
The allocated storage must greater than the reserved base
storage
-
The allocated storage, rounded up the nearest 1TB, can be
reduced by 1TB or more
-
Allocated storage – Used storage > 100GB.
The shrink operation is not allowed if
ADB contains:
-
Advanced Queuing tables
-
Tables with LONG columns
The overview of Activity charts under
Database Dashboard provide information about the performance of ADB.

The number of OCPU allocated chart
illustrates the average number of OCPUs allocated to the database per hour.
When auto scaling is enabled, for each hour, the chart shows the average number
of OCPUs used during that hour, if that value is higher than the number of
OCPUS provisioned. However, if the number of OCPUs used is not higher than the
number of OCPUs provisioned, then the chart shows the number of OCPUs allocated
for that hour.

For
example, this chart shows that this ADB scales up to 12 OCPUs and then back
down to 4 OCPUs as the workload increase or decrease over time.
5.
Auto indexing
With automatic indexing, the database
monitors the application workload, creates and maintains indexes automatically.
The indexing features is implemented as an automatic task that runs at fixed
intervals.

Machine Learning algorithms adapts to
changes and find new optimal plans and indexes. With automatic indexing, we are
able to detect if there are any workload changed and look for a suitable
candidate to introduce and index. Optimizer continuously capture new SQL
statements and changes in data volume, SQL plans adapt as the data volume
changes and new indexes are created if they speed off new SQL.
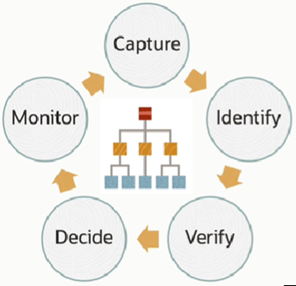
-
Periodically captures
all SQL statements and executions times (plans, bind values, execution
statistics
-
Identify candidate indexes (indexes are create
as unusable and invisible)
-
Verify use in new SQLs (Ask the optimizer if
those candidates will actually use those indexes; if not, the indexes are
automatically dropped by the optimizer. If there are used, it will complete the
creation of those indexes and it will verify that the performance is actually
improved)
-
Decide: if the performance is better for all
statements, the indexes are marked as visible; if not, the indexes are dropped.
-
Index usage is continuously monitored. Indexing activities are viewable, controllable and
auditable.
Auto Indexing is disabled by default
in ADB. If auto indexing is enabled, all the schema can used auto indexing by
default. You can configure it by using dbms_auto_index.configure procedure.
-
dbms_auto_index.configure(‘AUTO_INDEX_MODE’,’IMPLEMENT’): enable automatic indexing and creates
any new indexes as visible indexes, so they can be used in SQL statements
-
dbms_auto_index.configure(‘AUTO_INDEX_MODE’,OFF): disable automatic indexing, so no new
indexes are created but existing automatic indexes will remain enabled.
-
dbms_auto_index.configure(‘AUTO_INDEX_MODE’,’REPORT
ONLY’):
enable automatic indexing and creates any new indexes as invisible indexes, so
they cannot be used on SQL statements.
-
dbms_auto_index.configure(‘AUTO_INDEX_RETENTION_FOR_AUTO’,’373’): Is used to specify a period for
retaining unused auto indexes. The unused auto indexes are deleted after the
specified retention period. In this example, the retention period for unused
indexes is 373 days (Default value).
The AUTO_INDEX_SCHEMA
parameter can be used specify the schema that can be used auto indexes.
-
dbms_auto_index.configure(‘AUTO_INDEX_SCHEMA’,’SH’,’FALSE’): Adds the SH schema to the exclusion
list, so that SH schema cannot use the auto indexes.
-
dbms_auto_index.configure(‘AUTO_INDEX_SCHEMA’,’SH’,’NULL’): removes the SH schema to the
exclusion list, so that SH schema can use the auto indexes.
You can use SQL Developer Web to
display auto indexing configuration and reporting page. It only available if
you sign as into dedicated ATP as user with administrator rights.
6.
ADB Connectivity
In ADB, predefined services minimize Application
Impact. Concurrency and prioritization of user requests is determined by the
database server the user is connected with. You are required to select a
service when you connect to the ADB.
The service names for ADB connections
generally are in the below formats:
|
Workload Type |
Service Names |
|
ADW |
dbname_high dbname_medium dbname_low |
|
ATP |
dbname_tpurgent dbname_tp dbname_high dbname_medium dbname_low |
|
AJD |
dbname_tpurgent dbname_tp dbname_high dbname_medium dbname_low |
These services map to the high, medium
or low consumer groups. The basic characteristics of these consumer groups are:
-
high: Highest resources, lowest concurrency
and allows queries to be run in parallel
-
medium: Less resources, high concurrency and
allows queries to be run in parallel
-
low: Least resources, high concurrency
and queries run serially (No Parallel)
-
tp_urgent: Highest priority application
connection service for time critical- transaction processing operations. This
connection supports manual parallelism
-
tp: A typical application connection
service for transaction processing. This connection does not run parallelism

For example, for an ADB with 16 OCPUs,
The high consumer group will be able to run 3 concurrent SQL statements when
the medium consumer group is not running any statements. The medium will be
able to run 20 (1.25 x 16) current SQL statements when the high consumer group
is not running any. The low consumer group will be able to run 1600 (100 x 16)
current SQL statements.
The high consumer group can run at
least one SQL statement when a medium consumer group is also running
statements. When the concurrency levels are reached for the medium and high
consumer groups, new SQL statements in that group will be queued until one or
more running statements finish.
Applications connect to a predefined
database service to control relative priority, SQL parallelism, max
concurrently executing users. For example, most OLTP applications connect to
“TP” service, most Batch to “LOW” service.


Aucun commentaire:
Enregistrer un commentaire